앞서 1편에서 공유 드린 바와 같이, ‘선물 추천 챗봇 만들기’로 정말 저를 갈아 넣어서 기획서를 작성하고 좋은 평가를 받았으나, 현실적인 이유로 원래의 목적을 살리되, scope를 줄여 ‘향수 추천 챗봇 만들기’로 프로젝트 타겟을 축소하였습니다.
좋은 결과물을 위해 필요로 하는 조정을 두려워 하지 말자
하지만, 이러한 조정이 마냥 아쉽지 만은 않았던 까닭은, 사실 처음 기획을 하면서, (다른 팀원들에겐 이야기하지 않았지만) 한 차례 정도의 타겟 축소를 이미 계획하고 있었기 때문입니다. 다양한 카테고리의 상품에 대한 충분한 리뷰를 스크래핑하고 이를 전처리 한 후, 키워드 추출 및 알맞게 가공하는 과정 등이, 주어진 시간과 인력 조건 상 많이 빠듯한 상황이었거든요. 그렇기에, 매주 팀원들에게 진행 상황을 공유하고 논의하며, 모두가 동의하는 적절한 시점에 타겟 카테고리를 조정하였습니다.
아시죠? 꿈을 크게 꾸어야, 비록 그 꿈을 이루진 못해도 그 꿈에 더 근접한 결과물을 내놓는다는 것을 🙂
사실, 최초로 기획한 ‘선물 추천 챗봇 만들기’는 단순히 ‘리뷰를 모아서 알맞은 선물 챗봇을 만든다’보다 더 다양한 구현을 필요로 했습니다. 그만큼, 사업적으로 인정 받을 수 있는 아이디어와 단계별 구현까지 이미 개인적으론 만들어둔 상태였습니다. 비록, 이번 프로젝트에서는 현실적인 이유로 이를 다 구현해내지 못했지만, 원래의 프로젝트 기획안은, 추후 적절한 팀원들과 적절한 시점에 좋은 프로젝트를 통해 다시 구현하는게 작은 목표이기도 합니다 🙂
챗봇의 기반 지식이 될 향수 리뷰 데이터를 모아보자
향수 카테고리로 목표 카테고리를 정한 후, 향수 리뷰 데이터를 얻기 위하여 향수를 판매하는 사이트들의 데이터를 활용하기로 하였습니다. 그리고, 토론을 통해 C사, M사, N사, O사의 향수 리뷰 데이터를 스크래핑 해오기로 했습니다.
용어 정의: 크롤링? 스크래핑?
보통, 웹에서 데이터를 수집하는 과정을 ‘크롤링(Crawling)’이라고 합니다. 하지만, ‘스크래핑(Scraping)’이라는 용어 또한 있는데요. 이 두 가지는 데이터를 수집/추출하는 방법에 따라 구분이 됩니다.
크롤링(Crawling): 웹 페이지들을 자동으로 탐색하고, 해당 페이지들의 링크를 탐색하여 데이터를 수집하는 일련의 과정을 의미합니다. 크롤링은 검색 엔진의 탐색 및 정보 수집 방식을 예로 들 수 있습니다.
스크래핑(Scraping): 특정 웹 페이지의 원하는 데이터를 추출하는 것이 주목적인 일련의 과정을 의미합니다. 스크래핑은 특정 웹 페이지의 상품 페이지에서 해당 상품의 정보와 리뷰, 평점 등의 특정한 데이터만을 추출하는 과정을 예로 들 수 있습니다.
즉, 향수 추천 챗봇을 만들기 위해 특정 상품 페이지의 상품 정보, 리뷰, 평점 등을 가져오는 작업은 ‘웹 스크래핑’이라고 할 수 있습니다.
웹스크래핑은 어떻게 하나요?
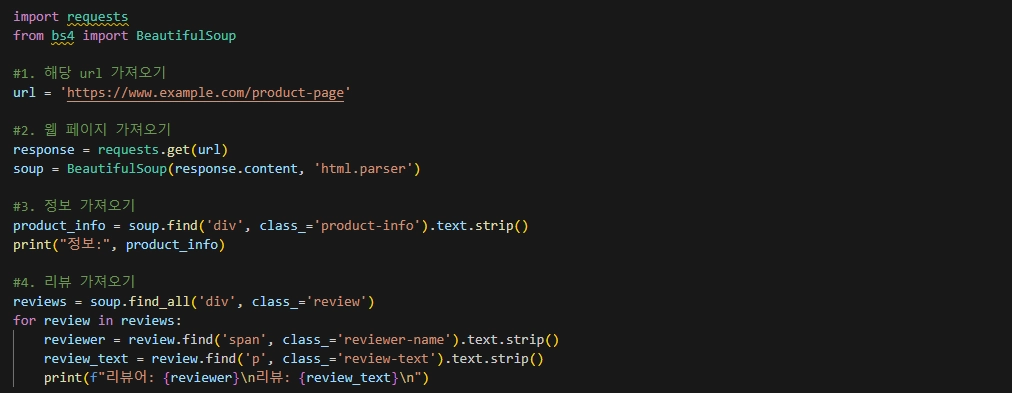
웹스크래핑은 파이썬에서는 주로 BeautifulSoup과 requests 라이브러리를 이용해 수행합니다. 아래의 코드가 웹스크래핑을 위한 코드의 예입니다.
웹 스크래핑 코드 예시
특정 사이트에서 원하는 정보를 가져오기 위해서는, 1, 2) 원하는 url에 get 요청을 보내고, 그 응답을 parsing한 후 BeautifulSoup 객체로 저장해줍니다. 3, 4) 이후, 특정 조건(클래스 이름 등)에 해당하는 요소를 찾아 원하는 데이터를 추출하여 저장합니다.
위의 코드는 예시로, 원하는 데이터를 얻고자 하는 조건에 따라 수정 및 추가, 변경이 필요로 합니다. 자세한 코드는 추후 저의 github를 통해 공유 드리도록 하겠습니다.
원하는 사이트의 리뷰 데이터를 가져오는 것이 가능한가요?
네. 가능합니다. 다만, 각 사이트는 웹 크롤링, 스크래핑에 대한 규칙을 각기 다르게 정해놓고 있는데요. 각 사이트에서 Robots.txt을 통해 그 규칙을 확인할 수 있습니다.
robots.txt
해당 txt 파일은, 각 사이트의 도메인주소 뒤에 /robots.txt를 붙여 확인할 수 있습니다. 예를 들어, 네이버의 경우, www.naver.com/robots.txt에서 네이버의 규칙을 확인할 수 있습니다.
대개의 경우에, 검색 엔진으로부터의 크롤링을 통해 자신의 사이트가 노출되는 것을 원하기 때문에 웹 크롤링을 원천적으로 불가하게 두지는 않지만, 만일 웹 크롤링 및 웹 스크래핑을 통해 추출한 데이터를 상업적으로 이용하실 경우 문제가 될 수 있습니다. 이에 대해서는 요 몇 년 새에 기업 간에 있었던 해당 사이트가 보유한 데이터에 대한 소유 문제 등에 대한 법적 분쟁 등을 참고하실 필요가 있습니다.
비정상적인 접근 판정을 피하기 위해 time.sleep, 서버 등을 활용하기
또한 많은 사이트들은 이러한 수집을 위한 접근이 자주 일어날 경우, 해당 접근을 비정상적인 접근으로 여겨 (심할 경우) 해당 사이트의 접근 자체를 막는 조치 등의 제한조치를 취할 수 있습니다.
예를 들어, 쿠팡의 경우, 비정상적인 접근으로 판정될 경우, 해당 위치의 네트워크가 쿠팡에 아예 접근하지 못하도록 접근 금지 등으로 접근을 막는 경우도 있으니, 주의하셔야 합니다.
이를 피하기 위해, 해당 과정 중 time.sleep() 등의 조건을 두어 접근의 속도를 조정하거나, 몇 가지 다른 방법으로 접근 제한 조치를 대비해야 합니다.
웹 스크래핑 결과 데이터 살펴보기
웹스크래핑으로 추출한 제품명, 평점, 작성일, 리뷰 제목, 리뷰 본문, 만족도, 지속도 평가 정보
위의 데이터는 제가 C사의 각 제품 페이지에서 추출해온 제품명, 평점, 리뷰 작성일, 리뷰 제목, 리뷰 본문, 만족도 평가, 지속도 평가에 대한 정보입니다. 깔끔하게 잘 추출이 되었지요?
데이터, 추출해서 모으면 끝? 필요해, 전처리!
하지만, 잘 보시면, 데이터에서 손 봐야 할 곳이 많이 보입니다.
예를 들어, 같은 제품이지만, 용량 등의 정보가 다르거나 기재하는 방식이 다른 경우들이 있습니다. 또한, 리뷰에 따라 특정 정보들이 없는 경우들도 있고, 바로 해당 데이터들을 사용할 수 없게 하는 여러 문제들이 있습니다.
추출한 데이터를 원하는 목적에 맞게 사용하기 위해 가공하는 단계를 ‘전처리’라고 합니다.
참고로, 제가 4개월 간 해당 과정과 또 타 과정에서 가장 돋보였던 지점 중 하나가 바로 이 ‘전처리’를 가장 효율적이고 알맞게 하는 것이었습니다. 아무래도 살아온 세월이 있다 보니, 경험이 도메인이 되어서 그런게 아닌가 싶습니다.
이에 대해서는, 이어지는 3. 데이터 전처리하기 편에서 공유 드리도록 하겠습니다.
RAG 기반 향수 추천 챗봇 라이브 시연 영상 (제작 및 시연: 소울새싹(SoulSesac) in 안테나곰)





")